Training Models with Mantra¶
Once you have some datasets and models, you can easily train them (a) locally and (b) on the cloud.
🏃 Training Locally¶
From your project root:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50
If you have a task that you want to train with:
$ mantra train my_model --dataset my_dataset --task my_task --batch-size 64 --epochs 50
Additional magic model hyperparameters can be referenced:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50 --dropout 0.5
For image datasets, you can specify things like dimensions:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50 --image-dim 256 256
For table datasets, you can specify features and targets:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50 --target my_target --features feature_1 feature_2
If you only want to save the best model weights:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50 --savebestonly
🚂 Training on AWS¶
To train a model on AWS, first configure your AWS credentials
$ mantra cloud
You will be asked for your your AWS API keys and AWS region preferences. Once complete make sure you have AWS CLI installed - this is a necessary dependency! You will also need to ensure your security group has the right permissions - e.g. ability to create and shut down instances.
Make sure to check the settings.py file and ensure that the instance type and AMI you want to launch are right for you. Most of the functionality has been tested with the AWS Deep Learning AMI. Depending on what type of instance you want to launch, you might need to contact AWS to ask them to increase your instance limit.
Danger
RESERVED AWS GPU INSTANCES CAN BE VERY EXPENSIVE TO TRAIN ON. ALWAYS ENSURE YOU ARE AWARE WHAT INSTANCES ARE RUNNING AND IF THEY HAVE BEEN PROPERLY SHUT DOWN OR TERMINATED
To train with the cloud, there are two main options. First you can spin up a reserved instance and close once training is complete. To do this just use the cloud flag:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50 --cloud
For model development, it’s recommended to using a –dev flag:
$ mantra train my_model --dataset my_dataset --batch-size 64 --epochs 50 --cloud --dev
This will create a development instance that isn’t terminated when training completes. This means you can use the same instance to run models on - it means setup time is a lot quicker (as all the dependencies are already sorted out). You can still shut this instance down when you’re not using it - and when you do need to use it again, training will automatically turn the instance on again.
You can see what mantra GPU instances are running on the cloud tab of the UI:
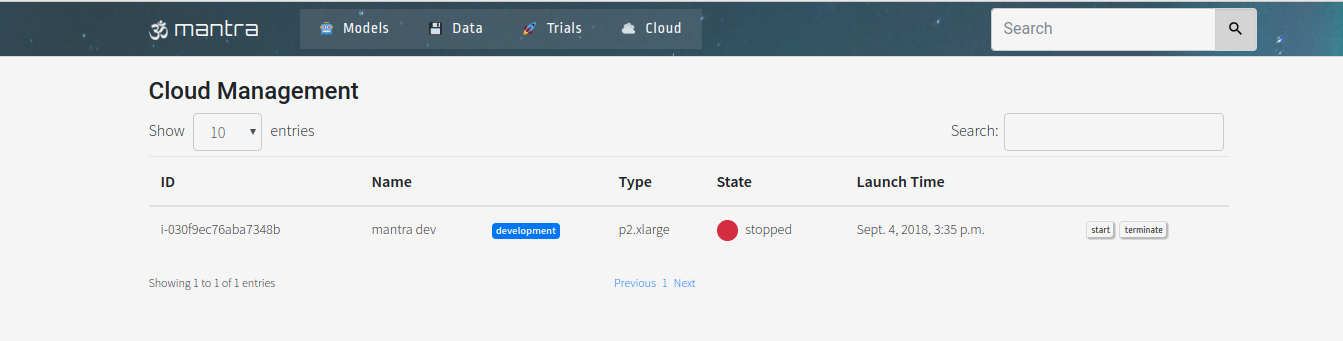
This is no substitute for checking on AWS itself what instances are running - always stay aware!
The other thing to be aware of is S3 storage costs. Mantra uses S3 as a central storage backend for datasets and also data that is generated during training - such as model weights. You can see your bucket name in settings.py. Be aware of how much you are currently storing, and if you are cost conscious, then remove files in S3 that you are no longer using.