Defining Tasks with Mantra¶
In mantra a task combines evaluation metrics with definitions of the training/validation/test data. Making a task is like creating your own machine learning competition : here is the training and test set, and here is what your models will be evaluated on.
🏆 Make a Task¶
Go to the root of your project. To make a new model we can use the makemodel command:
$ mantra maketask my_task
Our new task folder will be located at myproject/tasks/my_task. Inside:
__init__.py
task.py
task.pycontains your core task logic
Let’s have a look at the task.py file and see what the template contains:
from mantraml.tasks import Task
class MyTask(Task):
task_name = 'My Example Task'
evaluation_name = 'My Evaluation Metric'
training_split = (0.5, 0.25, 0.25)
def evaluate(self, model):
# Return an evaluation metric scalar here. For example, categorical cross entropy on the validation set:
# predictions = model.predict(self.X_val)
# return -np.nansum(self.y_val*np.log(predictions) + (1-self.y_val)*np.log(1-predictions)) / predictions.shape[0]
return
The training_split variable is a tuple that specifies what proportion of the data to use for training, validation and test respectively.
In the evaluate function we take a mantra model as an input and evaluate it according to a logic of our choice. In the commented out notes, we see an example for categorical crossentropy that is referencing the validation set in the task.
What this code will do is when we run a model for a dataset on a task, at the end of each epoch, we’ll call the evaluate function to obtain a metric and this will be stored. So whatever you write in this method will be your evaluation metric.
Let’s look at a full example for binary crossentropy:
import numpy as np
from sklearn.metrics import accuracy_score
from mantraml.tasks import Task
class BinaryCrossEntropy(Task):
"""
This class defines a task with binary cross entropy; with a 0.50/0.25/0.25 training/test split
"""
task_name = 'Classifier Evaluation'
evaluation_name = 'Binary Crossentropy'
training_split = (0.5, 0.25, 0.25)
secondary_metrics = ['accuracy']
def evaluate(self, model):
predictions = model.predict(self.X_val)
return -np.nansum(self.y_val*np.log(predictions) + (1-self.y_val)*np.log(1-predictions)) / predictions.shape[0]
def accuracy(self, model):
predictions = model.predict(self.X_val)
predictions[predictions > 0.5] = 1
predictions[predictions <= 0.5] = 0
return accuracy_score(self.y_val, predictions)
Here we have also specified secondary metrics - ‘accuracy’ - that will also be recorded during training.
Using a Task and Comparing Models¶
During training, reference the task as follows:
$ mantra train my_model --dataset my_data --task my_task
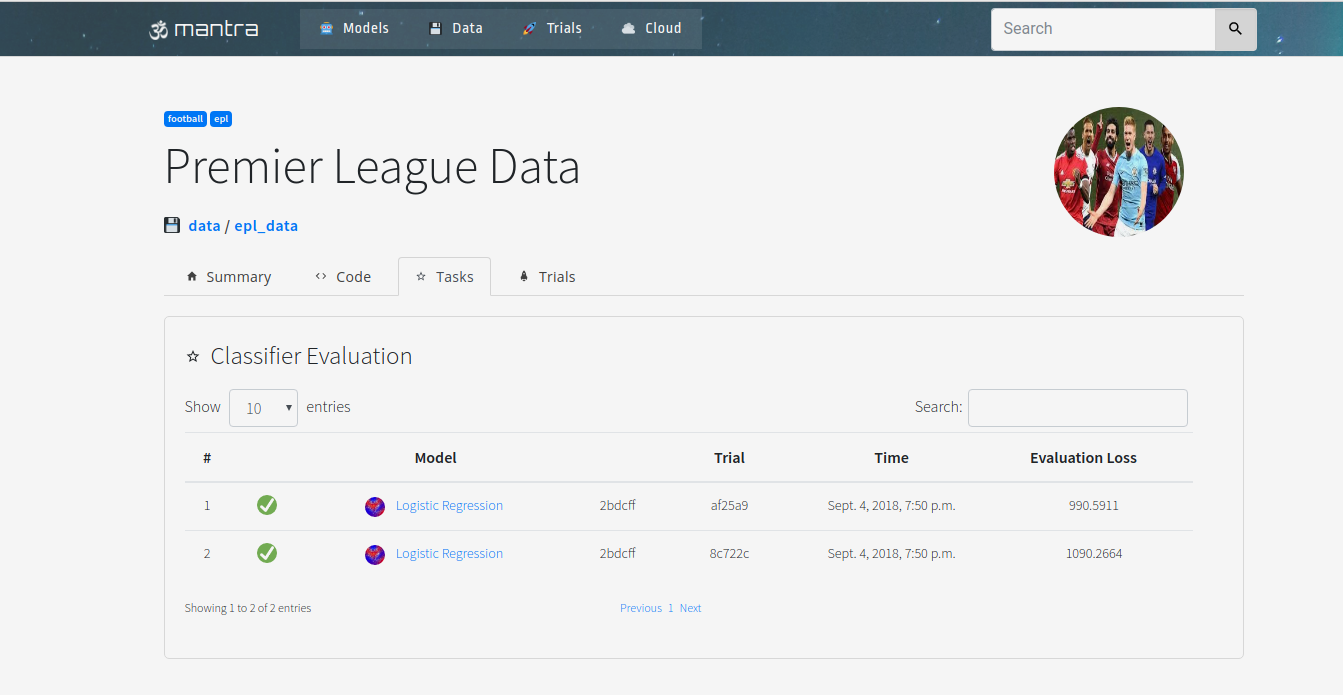
Using the UI we can visualize the performance of different models against tasks.
$ mantra ui
Below we can see a leaderboard for our task: